
What are eigenvalues and eigenvectors?
The hidden engine behind modern ML

Most engineers treat Linear algebra as something they “got through” in school. They import NumPy, call .fit(), and move on.
But underneath PCA, PageRank, facial recognition, recommender systems, spectral clustering, and the optimization analysis behind deep learning, there’s a single mathematical idea doing most of the work: eigenvalues and eigenvectors.
In this issue, we’ll build the intuition, walk through the most important applications, and look at how to use them in practice.
What eigenvalues and eigenvectors are
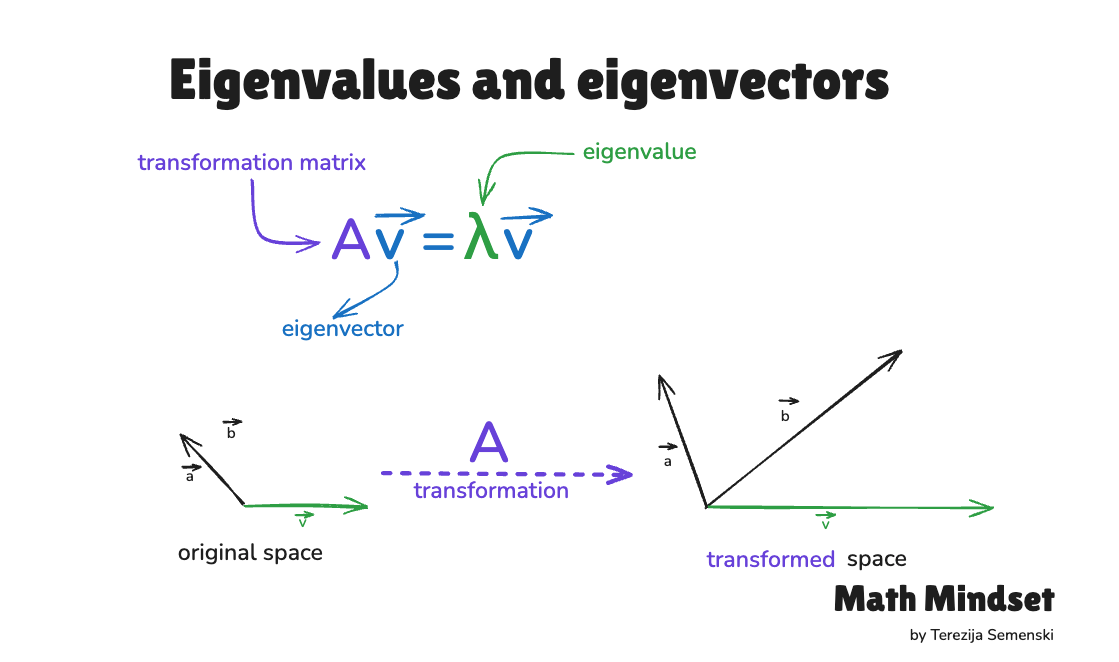
Every vector has two properties: a direction and a magnitude. When you multiply a matrix by a vector, both usually change, the vector rotates into a new direction and stretches or shrinks in length.
But some special vectors behave differently.
After the transformation, they stay on the same line. They may stretch, shrink, or flip, but they don’t rotate into a new direction. These are eigenvectors. The factor by which they scale is the eigenvalue.
We write it formally:
Av = λv
Where A is the matrix, v is the eigenvector, and λ is the eigenvalue.
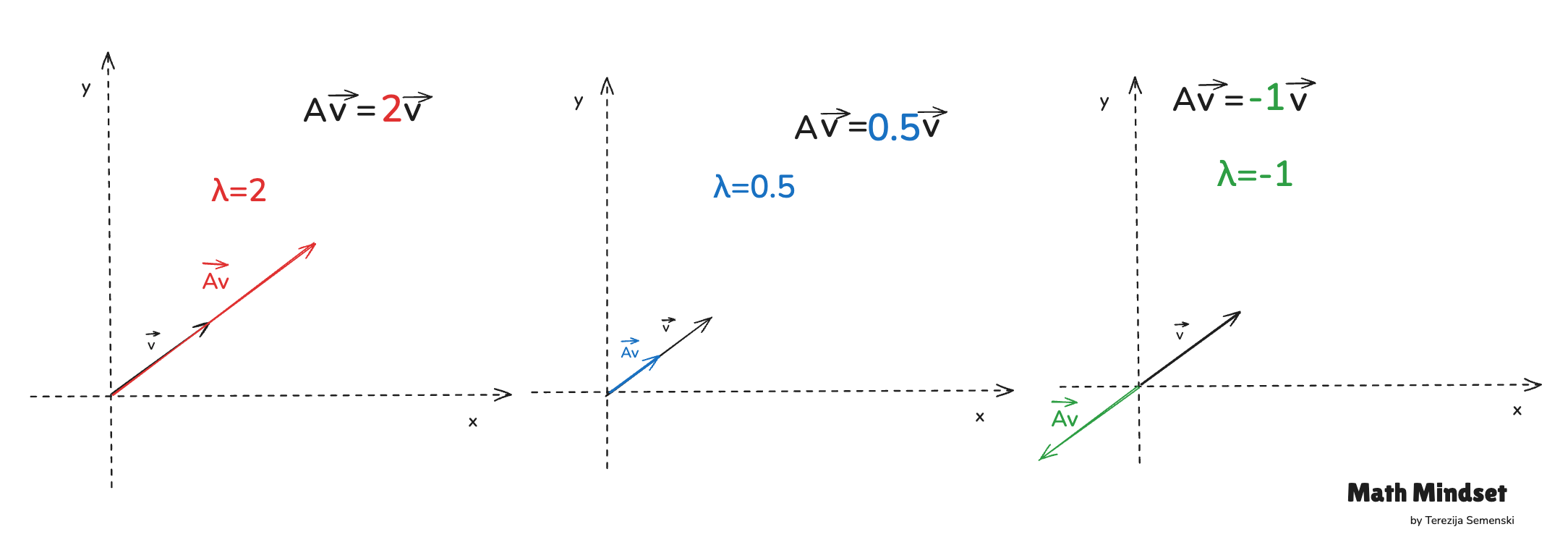
A few quick examples:
λ = 2 → the vector doubles in length
λ = 0.5 → the vector shrinks by half
λ < 0 → the vector flips direction and scales
(One technical caveat: real matrices can also have complex eigenvalues, rotation matrices are the classic example, in which case no real eigenvector exists.)
The intuition that matters:
Eigenvectors identify the important directions of a transformation. Eigenvalues measure how strongly the transformation acts along those directions.
That’s the entire idea. Everything else is application.
Why are they important in ML?
Modern ML works with high-dimensional data — images, text, audio, sensor streams, embeddings. A dataset can have hundreds, thousands, or millions of features.
Here’s the catch: not every direction in that feature space carries useful information. Some directions capture real structure. Others mostly capture redundancy or noise.
Eigenvalues are how we tell the difference.
The most important application: PCA
Principal Component Analysis (PCA) is built directly on eigenvectors and eigenvalues. The recipe is short:
Compute the covariance matrix of the dataset
Find its eigenvectors and eigenvalues
Use the eigenvectors with the largest eigenvalues as the principal components
Why does this work? Because the eigenvectors associated with the largest eigenvalues point in the directions of greatest variance in the data — and variance often corresponds to useful information. (Not always: PCA assumes variance equals signal, which can fail when the discriminative information lives in low-variance directions. Worth keeping in mind.)
The eigenvalues themselves tell you exactly how much variance each component captures. That gives you a principled way to reduce dimensionality while preserving most of the structure.
A concrete example. Suppose your dataset has 100 features. Training is slow, your model is overfitting, and many features are highly correlated. You apply PCA and inspect the eigenvalues:
The top 10 eigenvalues explain 95% of total variance
The remaining 90 explain only 5%
That tells you the data lives, effectively, in a 10-dimensional subspace. Train on those 10 components instead of all 100, and you get faster training, less memory pressure, reduced overfitting, and minimal information loss. No manual feature selection required.
Where eigenvalues show up across ML
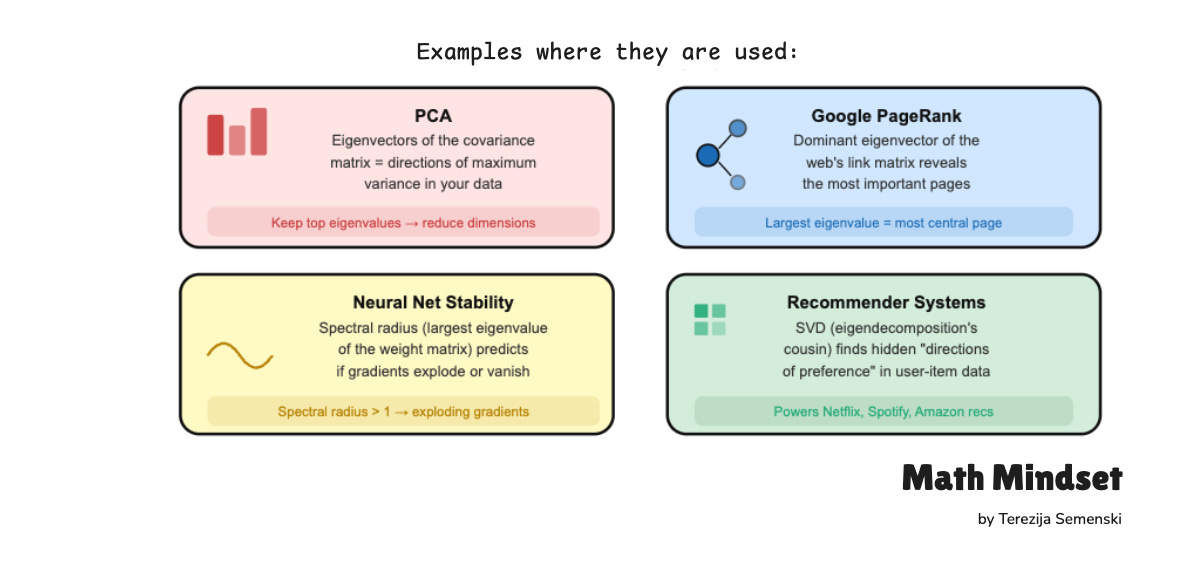
PCA and dimensionality reduction. Eigenvectors of the covariance matrix define the principal components; the eigenvalues determine how much each one preserves.
Noise reduction. In covariance-based methods, directions tied to very small eigenvalues often correspond to noise or weak signal. Discarding them improves robustness and compression.
Facial recognition (EigenFaces). One of the earliest face recognition systems represented faces as weighted combinations of “eigenfaces” :eigenvectors computed from a dataset of face images.
Google PageRank. PageRank computes the dominant eigenvector (corresponding to eigenvalue 1) of the Google matrix — a stochastic matrix derived from the web link graph with a damping term added. The entries of that eigenvector are the page importance scores. The same idea generalizes to ranking across networks and graphs.
Spectral clustering. Uses eigenvectors of the graph Laplacian to uncover structure in datasets where standard clustering struggles. The eigenvalue spectrum often hints at how many meaningful clusters exist.
Optimization and Hessian analysis. In deep learning, the Hessian captures the local curvature of the loss surface. At critical points, positive eigenvalues mean positive curvature along that direction, negative eigenvalues mean negative curvature, and mixed signs indicate a saddle point. This is how researchers reason about optimization stability and training dynamics.
Singular Value Decomposition (SVD). The singular values of a matrix A are the square roots of the eigenvalues of AᵀA. SVD powers recommender systems, matrix compression, latent semantic analysis, denoising, and low-rank approximation — much of practical linear algebra in ML rests on it.
Dynamical systems and stability. In differential equations, control systems, recurrent networks, and physical simulations, eigenvalues determine whether systems remain stable, oscillate, or diverge over time.
Key Takeaways
Eigenvectors identify the directions preserved by a linear transformation
Eigenvalues measure how strongly the transformation acts along those directions
Together, they reveal the structure inside complex matrices
In PCA, large eigenvalues correspond to high-variance directions
They enable dimensionality reduction, denoising, compression, and stability analysis
PCA, PageRank, spectral clustering, SVD, recommender systems, and optimization all rely on them
Eigenvalues and eigenvectors aren’t academic Linear algebra you can safely forget. They’re core tools behind the systems you’re already using. Spend an hour with them now and a lot of ML will look different by the end of the week.
P.S. Thank you for reading this far.
That alone puts you in rare company: most people scroll past anything that asks them to think slowly.
The fact that you’re here suggests you already value the kind of thinking this newsletter is about. Share it with someone who values it too. Those people are worth finding.
Until next week’s issue, keep learning, keep building, and keep thinking like a mathematician.
-Terezija